Book a Free Strategy Call
Skip the read: talk to Walid in 30 min.
Free strategy call. We map your AI engineering team, you keep the notes.
Claude Opus 4.7: What Actually Changed and What It Means for Developers
Claude Opus 4.7 landed on April 16, 2026, and if you blinked you might have missed it. Anthropic kept pricing identical to Opus 4.6 while shipping a set of targeted capability upgrades that matter a lot if you are running production AI workloads. This is not a marketing refresh. The changes are specific, measurable, and worth understanding before you decide whether to migrate.
This post breaks down every documented change in Opus 4.7 and tells you exactly what each one means for the systems you are building today.
What's New in Claude Opus 4.7
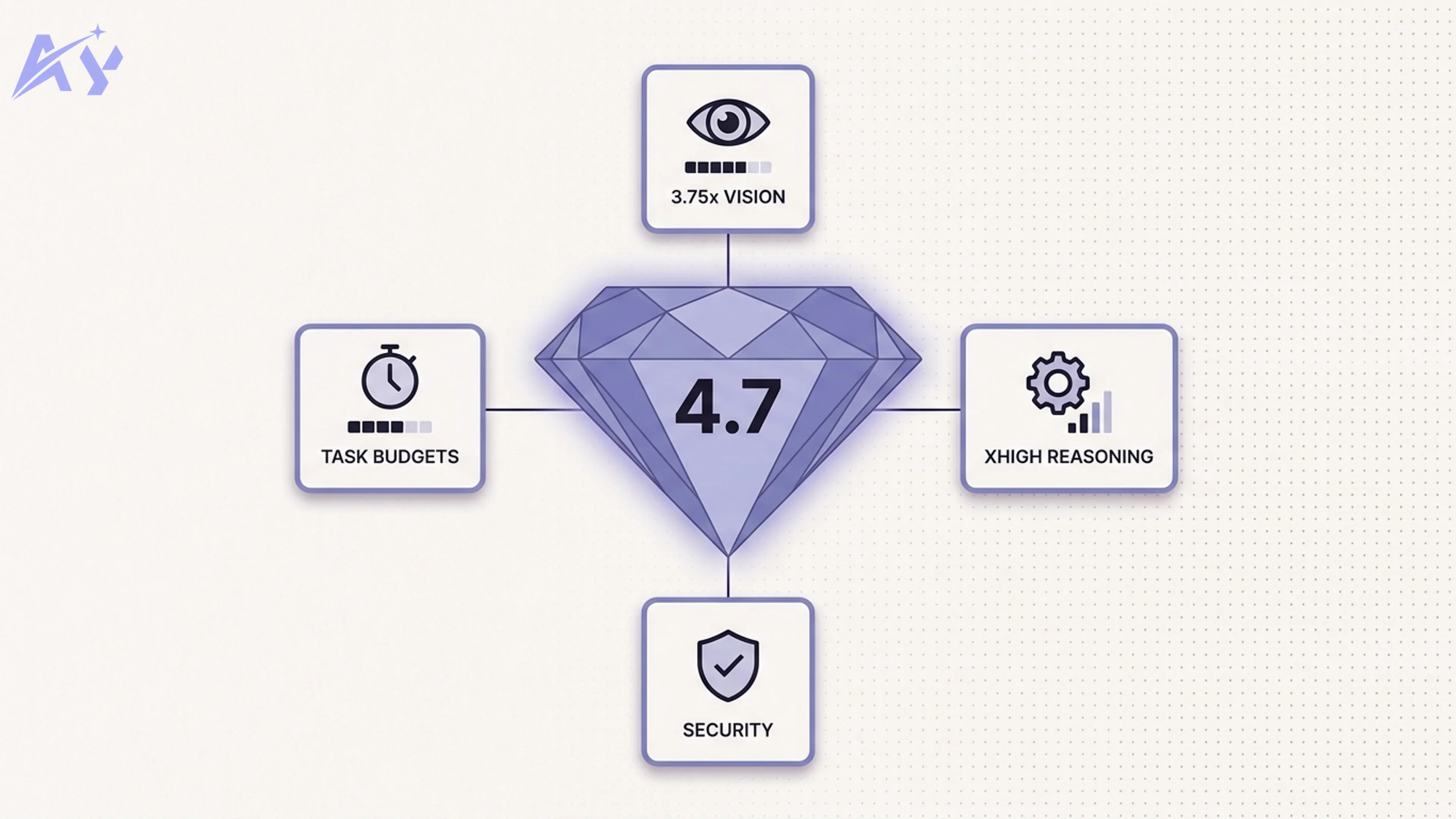
Anthropic shipped five substantive changes with Opus 4.7:
- Vision resolution increased to 2,576 pixels (3.75x improvement over Opus 4.6)
- A new "xhigh" reasoning effort level for deeper, more deliberate inference
- Agentic self-checking so the model can verify its own outputs mid-task
- Task budgets to give long-running agents structured stopping conditions
- Cybersecurity safeguards in a new built-in guardrail layer
There is also a companion product called Claude Design, a visual prototyping tool that launched alongside the model. We cover each of these below.
Related Reads
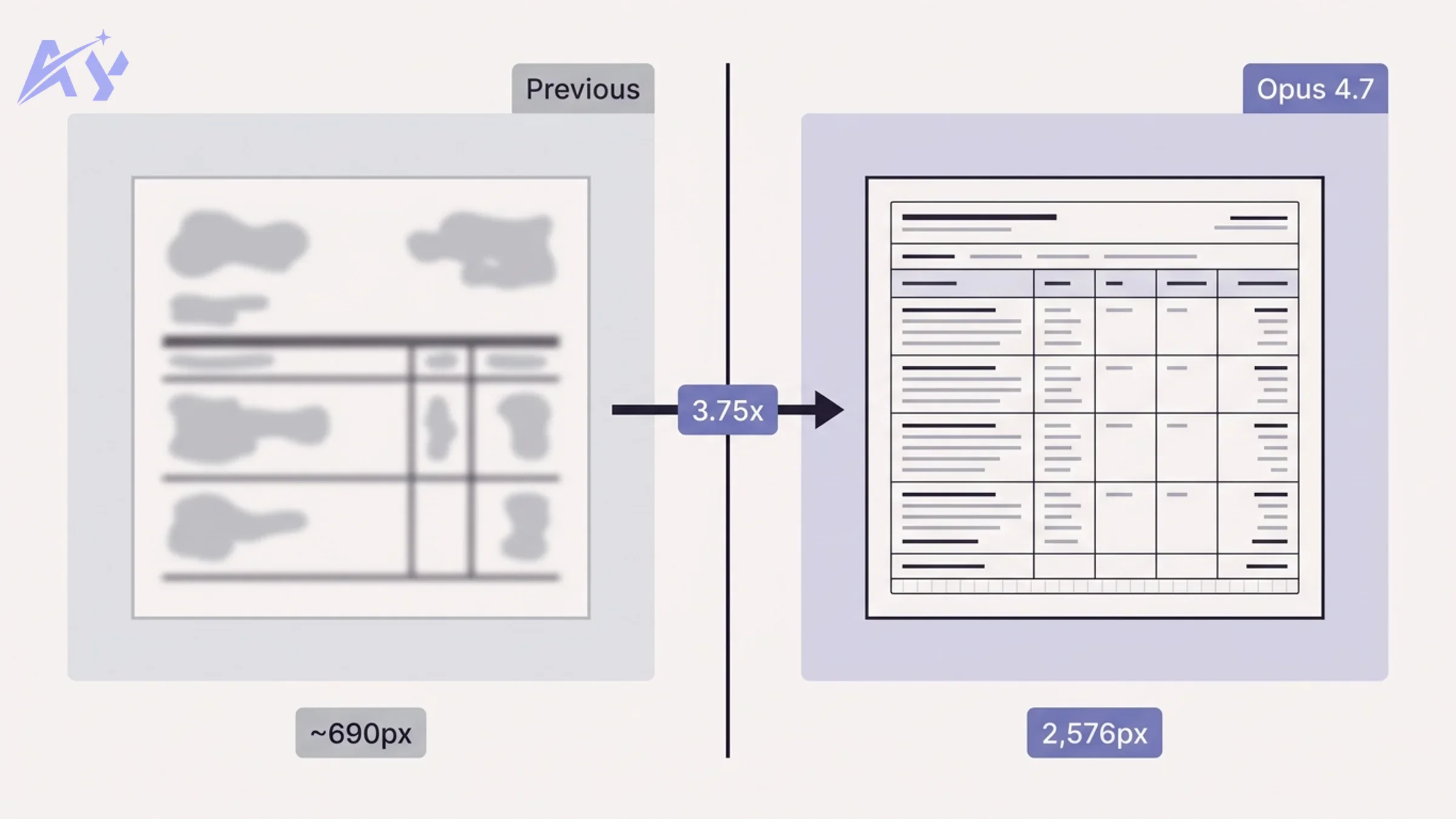
3.75x Higher Vision Resolution (2,576 Pixels)
The single most concrete upgrade in Opus 4.7 is vision. The model now processes images at up to 2,576 pixels on the long edge, compared to roughly 690 pixels in Opus 4.6. That is a 3.75x jump in linear resolution and roughly a 14x jump in total pixel area.
Why does this matter? Because most real-world document and UI analysis tasks break down exactly at the resolution boundary.
Document processing: Scanned PDFs, financial statements, engineering drawings, and medical records all have fine-grained structure that gets destroyed by downsampling. With Opus 4.6, you had to either chunk documents into smaller crops or accept degraded results on dense tables. Opus 4.7 can process a full A4 page at print resolution in a single pass. If you are running a RAG pipeline that ingests document images, this is a direct throughput and accuracy win.
UI and screenshot automation: Automating web interfaces requires reading small UI elements: form labels, error messages, dropdown values, date pickers. Low resolution forced workarounds like element-coordinate extraction via accessibility trees. Opus 4.7 can read most interfaces directly from a screenshot without needing a parallel DOM scrape.
Image analysis workflows: For image classification and content moderation use cases, higher resolution means the model can detect small objects, read text in images, and reason about fine-grained visual differences without preprocessing.
The practical implication: if your current pipeline is cropping, tiling, or preprocessing images to work around resolution limits, you can simplify that code significantly with Opus 4.7.
Free weekly brief
Steal our production automations
The exact n8n flows, Claude Code setups, and prompts we ship for clients, broken down step by step. No spam, unsubscribe anytime.
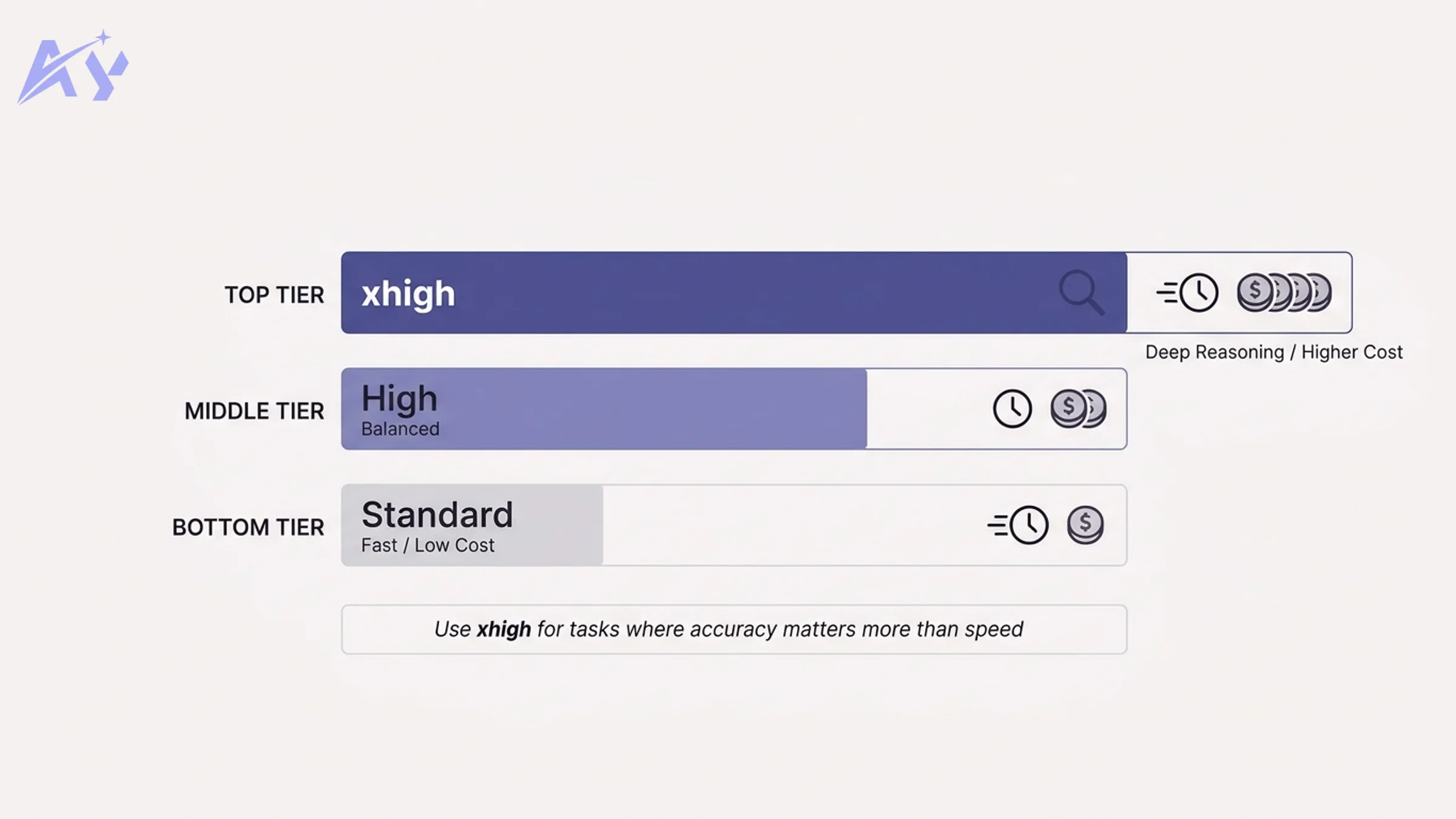
The xhigh Effort Level: Controlling Reasoning Depth
Opus 4.7 introduces a third reasoning effort tier: xhigh. Previously the API offered default and high. The new tier sits above both and tells the model to spend significantly more compute on intermediate reasoning before producing a final answer.
Here is how the three tiers compare in practical terms:
| Effort Level | Latency | Token Cost | Best For |
|---|---|---|---|
default | Fast (1-3s) | Base rate | Classification, extraction, summarization |
high | Moderate (3-8s) | 1.5-2x | Code review, planning, multi-step reasoning |
xhigh | Slow (8-20s+) | 2.5-4x | Complex math, legal analysis, architecture decisions |
The xhigh setting is not meant to be used universally. It is a precision tool for tasks where getting the answer right the first time is worth the extra latency and cost.
When to use xhigh: Tasks with high downstream cost of failure: financial modeling, compliance checks, clinical decision support, code that goes straight to production. Any scenario where you would otherwise loop back with a "are you sure?" follow-up prompt.
When to stay on default or high: Streaming UIs, interactive chat, any workflow where the user is waiting in real time, and any task where you can verify the output cheaply after the fact.
The key insight is that xhigh effectively shifts budget from retry costs to generation costs. If a default response fails 20% of the time and requires a retry, you may be spending more total compute than a single xhigh call that succeeds 95% of the time.
Agentic Self-Checking and Task Budgets
This is the upgrade that has the most structural implications for anyone building long-running agents.
Agentic self-checking means Claude 4.7 can now pause mid-task, evaluate whether its work so far is correct, and course-correct before continuing. In prior model versions, the model would produce output and stop. Any verification logic had to be implemented externally: a separate validation call, a human-in-the-loop checkpoint, or a downstream test suite. Opus 4.7 internalizes a layer of that verification.
In practice this looks like: the model generates a draft answer, internally runs a consistency check against the original instructions, flags any discrepancies it finds, and either revises or flags the inconsistency for the caller. For AI agent systems running multi-step tasks, this meaningfully reduces error propagation. A mistake in step 3 of a 10-step task no longer necessarily compounds through steps 4-10.
Task budgets are a complementary feature. A task budget is a structured constraint you pass to the model telling it how many steps, tokens, or tool calls it is authorized to use before it should stop and report back. Think of it as a resource ceiling with a reporting obligation.
Why this matters for builders: long-running agents have historically been difficult to operate because they could consume arbitrary resources before failing silently. Task budgets give you a clean mechanism to set limits, get partial progress reports, and decide whether to authorize more compute or hand off to a human. This directly addresses one of the main reasons agent pipelines have been hard to productionize.
Combined with self-checking, these two features move Claude closer to being a reliable autonomous worker rather than a capable-but-volatile one.
Cybersecurity Safeguards
Opus 4.7 ships with an expanded cybersecurity guardrail layer that Anthropic describes as designed for enterprise deployment. The specific mechanisms documented in the release cover three areas:
Prompt injection defense: The model has improved resistance to injected instructions in retrieved content. For RAG systems and document processing pipelines, this means a malicious string embedded in a customer-submitted document is less likely to override system-level instructions.
Tool call auditing: When operating in agentic mode, the model maintains a more explicit record of which tool calls it is making and why, making it easier to audit behavior post-hoc and detect anomalous patterns.
Output filtering: There is an expanded layer of content filtering specifically targeted at outputs that could directly enable cyberattacks: working exploit code, novel malware patterns, and instructions for system compromise.
For teams deploying Claude in enterprise environments where security review is a prerequisite, these safeguards are directly relevant to procurement discussions. If you are working through an enterprise AI setup or have compliance requirements around model behavior, Opus 4.7 is the first version with documented controls at this level.
The practical implication for most builders is more confidence that Claude will not be weaponized by adversarial inputs in your data pipeline. Prompt injection via retrieved content has been a real attack vector. Documented resistance, even if not absolute, is a meaningful compliance asset.
Claude Design: The Visual Prototyping Tool
Alongside Opus 4.7, Anthropic launched Claude Design, a purpose-built tool for visual prototyping. It is positioned as a design-to-code accelerator where you can describe a UI, see a rendered mockup, and then export working React or HTML code.
This is separate from the model capability upgrades but relevant context for product builders. The higher vision resolution in Opus 4.7 directly enables Claude Design's ability to process uploaded wireframes, reference screenshots, and design files at high fidelity.
Claude Design is an early access product as of April 2026 and is not covered in depth in this post. It is worth watching for teams that currently use AI for frontend code generation, as it introduces a more structured design-first workflow compared to plain-text prompting.
Should You Upgrade to Claude Opus 4.7 Now?
The short answer is: yes, if vision, agentic reliability, or enterprise security matter to your use case. No, if you are happy with 4.6 performance on pure text tasks and do not want the testing overhead.
Here is a more structured decision matrix:
| Use Case | Recommendation | Key Reason |
|---|---|---|
| Document intelligence (PDFs, invoices, forms) | Upgrade now | 3.75x resolution directly improves accuracy |
| UI automation and screenshot analysis | Upgrade now | Eliminates most image preprocessing workarounds |
| Long-running autonomous agents | Upgrade now | Self-checking and task budgets reduce failure rate |
| Enterprise RAG with compliance requirements | Upgrade now | Cybersecurity safeguards support procurement |
| Complex reasoning (legal, financial, code) | Upgrade and test xhigh | Measurable accuracy improvement at higher cost |
| High-volume text classification | Stay on 4.6 or use Haiku | Same text quality, no resolution benefit |
| Real-time interactive chat | Stay on 4.6 or Sonnet | Latency profile unchanged, no interactive benefit |
| Cost-sensitive batch pipelines | Evaluate after testing | Same pricing but check xhigh cost impact |
The most important thing to understand is that Anthropic held the price steady. There is no financial penalty for upgrading on a per-token basis. The only cost is testing time and any pipeline changes required to take advantage of new features like task budgets.
If you are unsure where Opus 4.7 fits in your architecture, an AI strategy review is a practical next step. The decision is more than about which model to call, it is about which features to wire in and how task budgets change your agent orchestration design.
Talk to the team about your Claude upgrade path
Key Takeaways
- Claude Opus 4.7 launched April 16, 2026 at the same price as Opus 4.6
- Vision resolution increased 3.75x to 2,576 pixels, directly improving document and UI workflows
- The new
xhighreasoning effort level enables deeper inference at higher cost and latency - Agentic self-checking lets the model verify its own mid-task outputs, reducing error propagation
- Task budgets give builders explicit resource limits and reporting checkpoints for long-running agents
- New cybersecurity safeguards cover prompt injection, tool call auditing, and output filtering
- Claude Design launched alongside as a visual prototyping tool
- Upgrade now for document processing, agent, or enterprise use cases. Stay on 4.6 for text-only, high-volume, or interactive workloads where you are already hitting your performance targets
Frequently Asked Questions
What is Claude Opus 4.7?
Claude Opus 4.7 is Anthropic's updated version of the Opus 4 model family, released on April 16, 2026. It introduces higher vision resolution (2,576 pixels), a new xhigh reasoning effort level, agentic self-checking, task budgets, and cybersecurity safeguards, all at the same API price as Opus 4.6.
How much does Claude Opus 4.7 cost?
Pricing is unchanged from Opus 4.6. Anthropic has not published a separate price tier for Opus 4.7. The xhigh reasoning effort level will consume more tokens per request, so effective cost increases if you adopt that feature, but the per-token rate is the same.
What is the xhigh reasoning effort level?
xhigh is a new reasoning effort parameter you can pass to the Opus 4.7 API. It instructs the model to spend more compute on intermediate reasoning before producing a response. This improves accuracy on complex tasks but increases latency and total token usage. It sits above the existing default and high effort tiers.
What is agentic self-checking in Opus 4.7?
Agentic self-checking is a feature where the model internally verifies its own mid-task outputs for consistency with the original instructions. Rather than requiring an external validation call, the model can flag discrepancies and revise before delivering a final answer.
What are task budgets in Claude Opus 4.7?
Task budgets are structured constraints passed to the model at the start of an agentic task, specifying how many steps, tool calls, or tokens the model is authorized to use. When the budget is reached, the model stops and reports current progress rather than consuming unbounded resources.
Does Claude Opus 4.7 replace Opus 4.6?
Anthropic treats 4.7 as an upgrade rather than a replacement. Developers on Opus 4.6 can continue using that version. Opus 4.7 is the recommended choice for new deployments and for existing deployments where vision quality, agentic reliability, or security controls are relevant.
Is Claude Opus 4.7 better for coding tasks?
Anthropic's release notes highlight the xhigh reasoning effort level as beneficial for complex code generation and code review tasks. For straightforward coding tasks, the improvement over 4.6 is marginal. The most meaningful coding improvement is indirect: better agentic self-checking means multi-step coding agents (those that plan, implement, and test in sequence) are more reliable.
What is Claude Design?
Claude Design is a visual prototyping tool Anthropic launched alongside Opus 4.7. It allows users to describe or upload design references and receive rendered mockups with exportable code. It is currently in early access and leverages Opus 4.7's improved vision resolution as part of its core functionality.
For teams evaluating Claude tooling alongside Opus 4.7's agentic capabilities: best Claude Code agencies lists teams building with the full stack; how to set up Claude Code walks the configuration; and best Claude Code hooks covers the productivity layer most teams add in week one.
Source: Anthropic official release announcement, April 16, 2026. https://www.anthropic.com/news/claude-opus-4-7
Continue Reading
Maestro vs Sakana Fugu: Open-Source vs Closed LLM Orchestration (2026)
Maestro handles multi-step reasoning tasks; Sakana Fugu routes jobs per token budget. Side-by-side comparison of orchestration, pricing, and limits.
7 Best Open-Source LLM Orchestration & Routing Tools (2026)
7 best open-source LLM orchestration tools 2026: Maestro for cost routing, LiteLLM for unified API, RouteLLM for research routing, Portkey for fallbacks.
What Is LLM Orchestration? Routing, Verify-and-Escalate & Cost Control (2026)
LLM orchestration coordinates multiple model calls across models and tools to complete one task instead of routing everything to a single expensive model.
Book a Free Strategy Call
Building this in production?
Walid runs a 30-min call to map your AI engineering team. Free, no slides.
Free weekly brief
Steal our production automations
The exact n8n flows, Claude Code setups, and prompts we ship for clients, broken down step by step. No spam, unsubscribe anytime.

Adel keeps the engine running at AY Automate. He owns internal processes, team coordination, and the operational excellence that lets us ship fast for clients.