Book a Free Strategy Call
Skip the read — talk to Walid in 30 min.
Free strategy call. We map your AI engineering team, you keep the notes.
What Is Sakana Fugu? The Orchestration Model Explained (+ How to Use It)
Prefer open-source? Maestro is an open-source, self-hostable take on Fugu. See Sakana Fugu alternatives and Maestro vs Sakana Fugu.
Sakana Fugu is an AI orchestration model from Sakana AI: a single LLM, served through one OpenAI-compatible API, that is trained to call other LLMs from an agent pool and handle model selection, delegation, verification, and synthesis on your behalf. Launched on June 22, 2026 by Sakana AI, the Tokyo-based R&D lab, it is best understood as "an AI project manager that hires a team" — a mathematician, a coder, a researcher, a reviewer — and decides when a tough question needs a second opinion. You send one request to one endpoint; Fugu figures out which underlying models should do the work.
This guide explains what Sakana Fugu actually is, how the orchestration works under the hood, the difference between Fugu and Fugu Ultra, how to use the Sakana Fugu API in Python and TypeScript, and where it genuinely makes sense versus where the skepticism is fair.
TL;DR
- What is Sakana Fugu: an orchestration LLM that routes each task across a pool of frontier models and returns one synthesized answer through a single OpenAI-compatible API.
- Two variants:
Fugu(balanced, low-latency — everyday coding, review, chatbots) andFugu Ultra(max quality for hard, multi-step problems; model IDfugu-ultra-20260615). - How it works: built on two ICLR 2026 papers — Trinity (Thinker / Worker / Verifier roles) and Conductor (reinforcement learning for coordination). It learns to coordinate rather than following hard-coded rules.
- How to use Sakana Fugu: get a key at
console.sakana.ai, then point any existing OpenAI client at Sakana's endpoint — change onlybase_url,api_key, andmodel. No SDK migration. - Why now: Sakana positions it as a hedge against single-vendor lock-in and export-control risk, explicitly citing the June 12, 2026 US export controls.
- The honest debate: the loudest community question is "is this just a router/wrapper?" Per-query routing is proprietary and hidden, and Fugu Ultra's pool is fixed with no opt-out.
What Is Sakana Fugu?
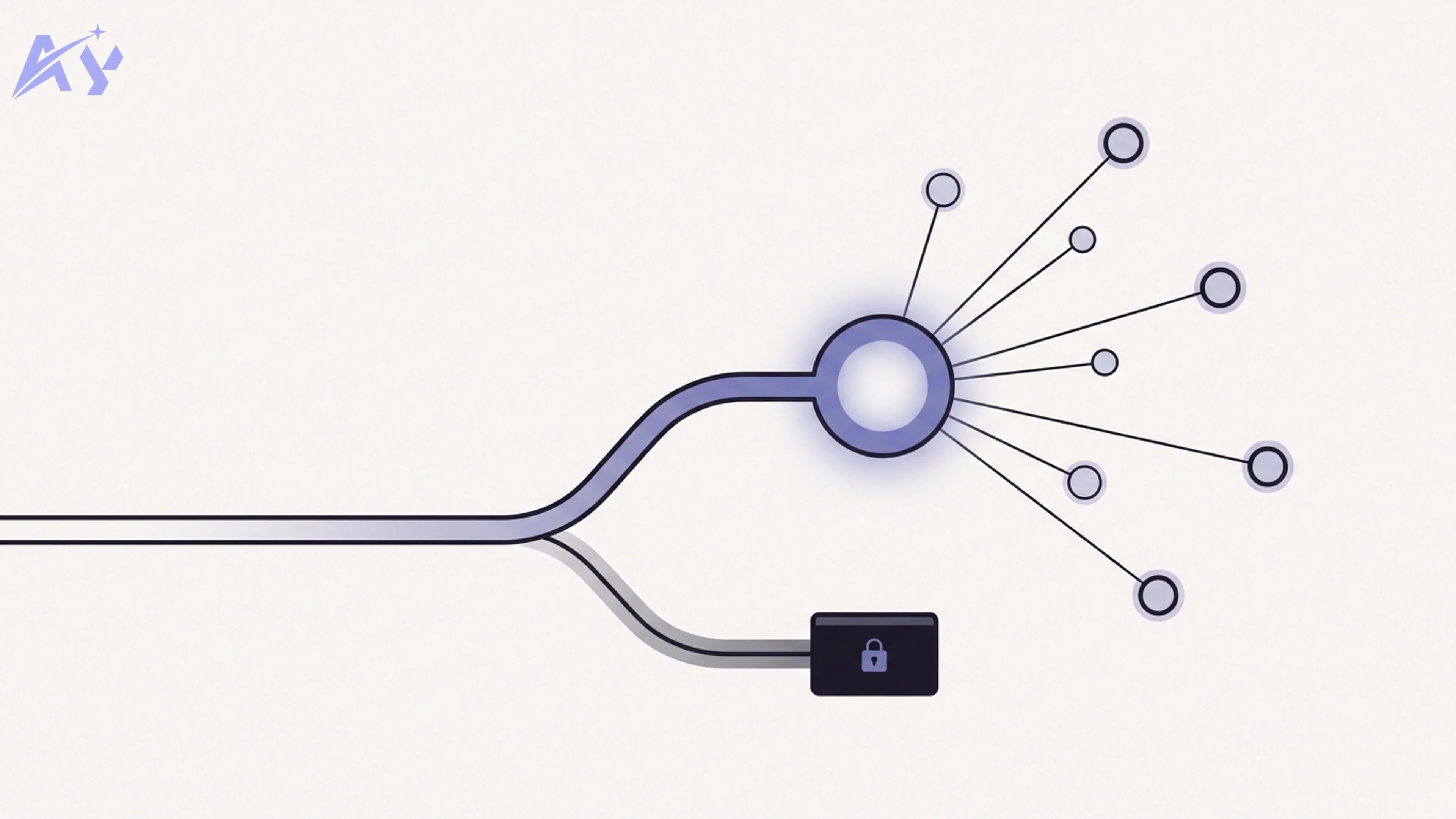
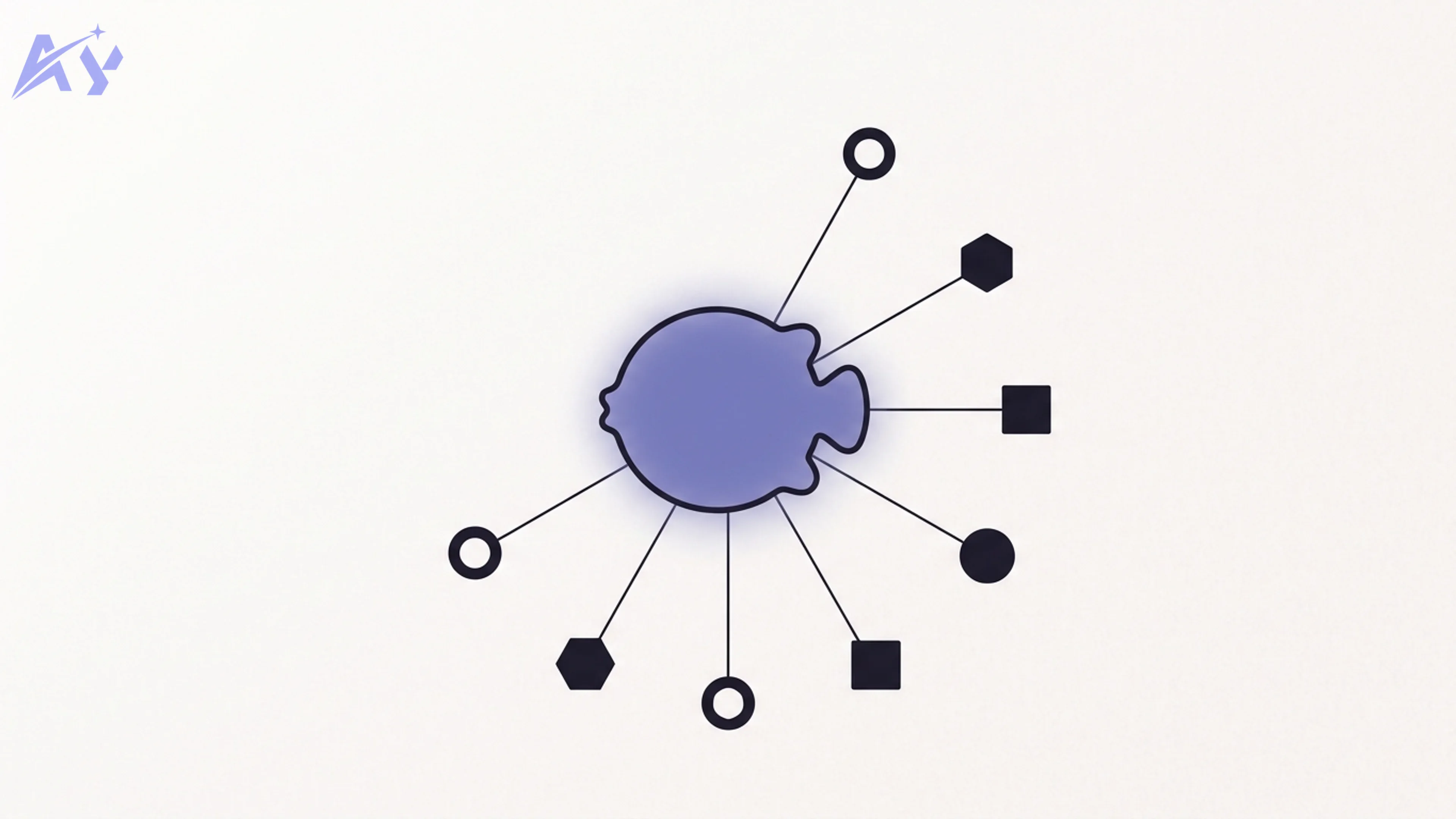
Sakana Fugu is a multi-agent orchestration model delivered as a single OpenAI-compatible API. The key idea is that Fugu is itself an LLM — but instead of answering every prompt directly from its own weights, it is trained to act as a coordinator that calls other models from an internal "agent pool." It handles four jobs you would otherwise wire up yourself: selecting which model fits the task, delegating the work, verifying the result, and synthesizing a final answer.
Sakana's own framing is that Fugu behaves like an AI project manager who hires a team. For a given request it can spin up the equivalent of a mathematician, a coder, a researcher, and a reviewer, route subtasks to each, and decide when an answer is shaky enough to warrant a second opinion. From the developer's seat, all of that is invisible: you call one model name and get one response back.
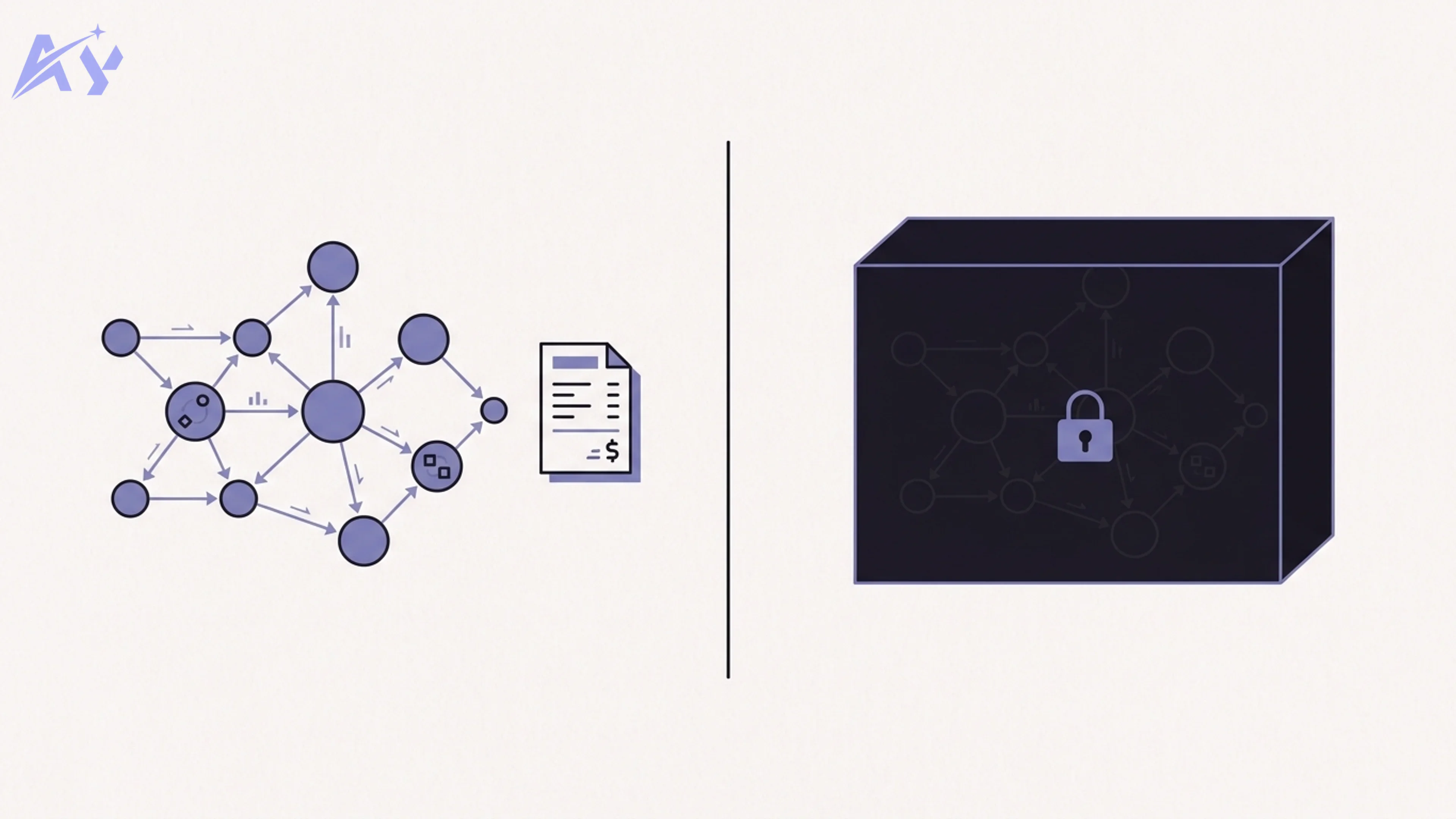
That single-endpoint design is the whole pitch. Multi-agent systems normally mean you orchestrate several providers, manage several SDKs, and write your own routing and fallback logic. Fugu collapses that into one API call. The trade-off — which we will be honest about below — is that the routing decisions happen inside a black box you do not control.
Sakana also frames Fugu as a strategic hedge. The launch was motivated explicitly by the June 12, 2026 US export controls, which is the same regulatory wave under which Anthropic's Fable 5 and Mythos were pulled by US export controls. Building on a single frontier vendor became a real continuity risk overnight, and an orchestration layer that can swap models behind a stable API is one answer to that risk. (Note: Fable 5 and Mythos are not in Fugu's pool — they are not publicly accessible. If you were relying on Fable specifically, see Claude Fable 5 alternatives.)
How the Orchestration Works (Trinity + Conductor)
Fugu is not a hand-written rules engine. It is built on two research papers Sakana presented at ICLR 2026, and the combination is what makes it interesting.
Trinity assigns three roles to the work:
- Thinker — reasons about the problem, decomposes it, and plans an approach.
- Worker — executes the actual subtasks (writing code, doing the math, drafting the research).
- Verifier — checks the Worker's output and flags when something needs a second pass or a different model.
This Thinker–Worker–Verifier split is what lets Fugu "decide when one model needs a second opinion." The Verifier role is essentially built-in quality control: instead of returning the first answer it generates, Fugu can catch a weak result and re-route it.
Conductor is the part that makes the roles adaptive. Rather than encoding fixed if-this-then-that routing rules, Conductor uses reinforcement learning to learn coordination strategies — which model in the pool to trust for which kind of task, when to escalate, when to verify, when to stop. The headline claim is that Fugu learns to coordinate rather than following a static playbook, so its routing improves on the dimensions it was trained to optimize.
The practical upshot: when you send a query, Fugu's learned policy decides how to break it down, which pool models to delegate each piece to, whether the result passes verification, and how to merge everything into one answer. You see the synthesized output, the token usage, and the cost — not the route it took to get there.
Fugu vs Fugu Ultra
Sakana ships two variants for two different cost/quality points.
| Fugu | Fugu Ultra | |
|---|---|---|
| Tuned for | Balanced, low-latency | Maximum answer quality |
| Best for | Everyday coding, code review, chatbots | Hard, multi-step problems |
| Model ID | fugu | fugu-ultra-20260615 |
| Trade-off | Speed and cost efficiency | Depth over latency |
| Pool | Routes across the pool | Fixed pool, no opt-out |
Use Fugu as your default workhorse: it is the low-latency option built for the high-volume work that fills most application traffic — code assistance, review, and conversational interfaces. Reach for Fugu Ultra when a request genuinely needs deep, multi-step reasoning and you care more about getting the right answer than about shaving milliseconds.
On quality, Sakana claims Fugu Ultra performs on par with Fable 5 and Mythos Preview — the very frontier models that the export controls put out of reach for many teams. That is a bold benchmark-level claim rather than something every user will independently confirm, so treat it as Sakana's position. We dig into the comparison in detail in how Fugu Ultra stacks up against Fable 5.
One caveat worth knowing up front: Fugu Ultra's pool is fixed, with no opt-out. You cannot tell it to avoid a particular underlying model or pin it to one you trust. If model-level control matters for compliance or reproducibility, that constraint is the thing to flag.
How to Use Sakana Fugu (the OpenAI-Compatible API)
This is the part that makes Fugu easy to adopt: it speaks the OpenAI API. You get an API key at console.sakana.ai, and then you use your existing OpenAI client libraries — no SDK migration. In practice you change exactly three things on a client you already have: base_url, api_key, and model.
Minimal Python example
from openai import OpenAI
client = OpenAI(
base_url="https://api.sakana.ai/v1", # point at Sakana's endpoint
api_key="YOUR_SAKANA_API_KEY", # key from console.sakana.ai
)
response = client.chat.completions.create(
model="fugu", # or "fugu-ultra-20260615" for hardest problems
messages=[
{"role": "user", "content": "Refactor this function and explain the trade-offs."},
],
)
print(response.choices[0].message.content)
# Token usage + cost are reported per request for real-time spend monitoring
print(response.usage)
Minimal TypeScript example
import OpenAI from "openai";
const client = new OpenAI({
baseURL: "https://api.sakana.ai/v1", // point at Sakana's endpoint
apiKey: process.env.SAKANA_API_KEY, // key from console.sakana.ai
});
const response = await client.chat.completions.create({
model: "fugu", // or "fugu-ultra-20260615"
messages: [
{ role: "user", content: "Review this PR for bugs and edge cases." },
],
});
console.log(response.choices[0].message.content);
console.log(response.usage); // per-request token usage + cost
That is the entire integration. If you already have an OpenAI-compatible app, switching to (or A/B testing) Fugu is a config change, not a rewrite. Because the OpenAI request/response shape is preserved, your streaming, error handling, and message structure all stay the same.
A useful operational detail: Fugu reports token usage and cost per request, so you can monitor spend in real time. This matters because of how billing works. There are subscription plans for daily use plus usage-based billing for bigger workloads, and your actual cost depends on which pool models a given query routes to — and that routing is proprietary and hidden. So the same prompt can cost different amounts depending on where Fugu sends it. There are no public price figures yet; we keep a running breakdown in Sakana Fugu pricing.
When Fugu Makes Sense (and When It Doesn't)
Fugu makes sense when:
- You want orchestration without building it. If you would otherwise stand up your own multi-model routing, verification, and fallback logic, Fugu hands you that as one API call.
- Single-vendor risk is a real concern. After the June 2026 export controls, a stable API in front of a swappable pool is a legitimate continuity hedge.
- You're already OpenAI-compatible. Adoption cost is near zero — three config values — so trialing it is cheap.
- Quality on hard problems matters more than control. Fugu Ultra targets exactly the multi-step problems where a single mid-tier model struggles.
Fugu is a weaker fit when:
- You need to know (or pin) which model answered. Routing is hidden and Fugu Ultra's pool can't be opted out of. For regulated, reproducible, or auditable pipelines, that opacity is a problem.
- You need Fable 5 or Mythos specifically. They are not in the pool. Fugu offers parity claims, not access.
- Predictable per-request cost is essential. Because cost depends on the hidden route, spend is variable by design — you monitor it after the fact rather than controlling it up front.
On the "is it just a wrapper?" criticism — honestly: this is the dominant question in the community, and it is a fair one. Fugu does sit in front of other models and route to them, which is the textbook definition of a router. The counter-argument is that the coordination itself is a trained model — Conductor's RL-learned routing and Trinity's verify-and-retry loop are not a thin if/else over an API list; they are the product. Whether that distinction is meaningful for your workload is something only your own evals can answer. The defensible position: don't take the orchestration's value on faith, and don't dismiss it as "just a wrapper" on reflex either. Benchmark it against a single strong model on your tasks and let the numbers decide.
Bottom Line
Sakana Fugu is a genuinely interesting bet: package multi-agent orchestration as one OpenAI-compatible model so teams get model selection, delegation, verification, and synthesis without building any of it, while hedging against single-vendor and export-control risk. The Trinity + Conductor foundation means the coordination is learned, not hand-coded, and the near-zero adoption cost makes it easy to trial. The open questions are about control and transparency, not capability: hidden per-query routing, a fixed Ultra pool, variable cost, and parity claims you should verify yourself. If you treat Fugu as something to benchmark rather than something to believe, it's a strong candidate for a default — especially for teams who want to stop being locked to one provider.
Building on Multiple Models?
If Fugu's pitch resonates but you want orchestration you actually control, that's the work we do. AY Automate builds production multi-model orchestration and failover systems so your team isn't locked to a single provider — with routing and fallbacks you can see and audit. If you're designing around model risk after the 2026 export controls, see our AI agent development work.
FAQ
What is Sakana Fugu? Sakana Fugu is an AI orchestration model from Sakana AI, launched June 22, 2026, and served as a single OpenAI-compatible API. It is an LLM trained to call other LLMs from an agent pool, handling model selection, delegation, verification, and synthesis internally — like an AI project manager that hires a team for each task.
How do I access Sakana Fugu?
Get an API key at console.sakana.ai, then use your existing OpenAI client library. You only change base_url to Sakana's endpoint, set your api_key, and pick the model (fugu or fugu-ultra-20260615). No SDK migration is needed because the API is OpenAI-compatible.
How do I use the Sakana Fugu API?
Point an existing OpenAI client at Sakana's base_url, supply your key, and call chat.completions.create with model="fugu" or model="fugu-ultra-20260615". The request/response shape matches OpenAI's, and token usage plus cost are returned per request for real-time spend monitoring.
What's the difference between Fugu and Fugu Ultra?
Fugu is the balanced, low-latency variant for everyday coding, code review, and chatbots. Fugu Ultra (model ID fugu-ultra-20260615) is tuned for maximum answer quality on hard, multi-step problems. Ultra's pool is fixed with no opt-out.
Is Fugu Ultra better than GPT-5.5 or Opus? Sakana claims Fugu Ultra performs on par with Anthropic's Fable 5 and Mythos Preview at the benchmark level. That is Sakana's own positioning rather than an independently universal result, so the honest answer is to benchmark Fugu Ultra against your current model on your own tasks before drawing a conclusion.
Is Sakana Fugu just a wrapper?
This is the most common community criticism, and it's partly fair — Fugu does route requests to other models. The counter-argument is that the coordination layer (Conductor's RL-learned routing and Trinity's Thinker–Worker–Verifier loop) is itself a trained model, not a thin if/else over an API list. Whether that distinction matters for you depends on your evals.
Does Fugu use Fable 5? No. Anthropic's Fable 5 and Mythos are not in Fugu's pool because they are not publicly accessible. Sakana claims parity with them via Fugu Ultra, but does not provide access to those models themselves.
Sources
Book a Free Strategy Call
Building this in production?
Walid runs a 30-min call to map your AI engineering team. Free, no slides.

Adel keeps the engine running at AY Automate. He owns internal processes, team coordination, and the operational excellence that lets us ship fast for clients.