Book a Free Strategy Call
Skip the read — talk to Walid in 30 min.
Free strategy call. We map your AI engineering team, you keep the notes.
Most teams running LLMs in production hit the same wall: one expensive model handles every request, easy or hard, and the bill climbs faster than the value. Open source LLM orchestration is the fix. Instead of hard-coding a single provider, you route each request to the cheapest model that can actually answer it, fall back when a provider fails, and keep the whole thing self-hosted and auditable.
This matters because routing is where the cost lives. The release of Sakana Fugu put cheap-first routing in the spotlight, and a wave of open source LLM orchestration tools now do the same thing without a closed platform. In this guide we compare seven of them, covering what each does well, real pricing, honest trade-offs, and a decision framework so you can pick the right open source LLM router for your stack.
Best open source LLM orchestration tools: a brief overview
- Maestro: Best for cost-transparent cheap-first routing: an open source orchestration brain that routes cheap-first, verifies, then escalates, and returns the full cost breakdown on every response. Built by AY Automate as a Sakana Fugu alternative.
- LiteLLM: Best for broad provider compatibility: one OpenAI-compatible interface in front of 100+ providers.
- RouteLLM: Best for research-grade cost routing: trained routers that send easy queries to a cheap model and hard ones to a strong model.
- Portkey Gateway: Best for production AI gateway features: routing, fallbacks, retries, caching, and observability in one gateway.
- Semantic Router: Best for fast intent and decision routing: embedding-based routing with no extra LLM call.
- LangChain / LangGraph: Best for full agent orchestration: build multi-step apps and stateful agent graphs, not just routing.
- Ollama: Best for local model serving: run open models locally behind an OpenAI-compatible endpoint, ideal as the "local" model in a pool.
| Tool name | Key strength | Pricing | Platforms |
|---|---|---|---|
| Maestro | Cheap-first routing with per-response cost transparency | Free, open source (self-hostable), MIT | CLI, Docker, OpenAI/Anthropic-wire API |
| LiteLLM | One OpenAI-compatible interface to 100+ providers | Free, open source (self-hostable) | Proxy, Python SDK, self-hosted |
| RouteLLM | Trained routers that cut cost while keeping quality | Free, open source (self-hostable) | Python framework, self-hosted |
| Portkey Gateway | Production routing, fallbacks, caching, observability | Free, open source (self-hostable); hosted option | Gateway, API, self-hosted or hosted |
| Semantic Router | Fast embedding-based routing, no LLM call | Free, open source (self-hostable) | Python library, self-hosted |
| LangChain / LangGraph | Full agent and multi-step workflow orchestration | Free, open source (self-hostable) | Python, JS/TS, self-hosted |
| Ollama | Local model serving via OpenAI-compatible endpoint | Free, open source (self-hostable) | macOS, Linux, Windows, local API |
1. Maestro, best for cost-transparent cheap-first routing
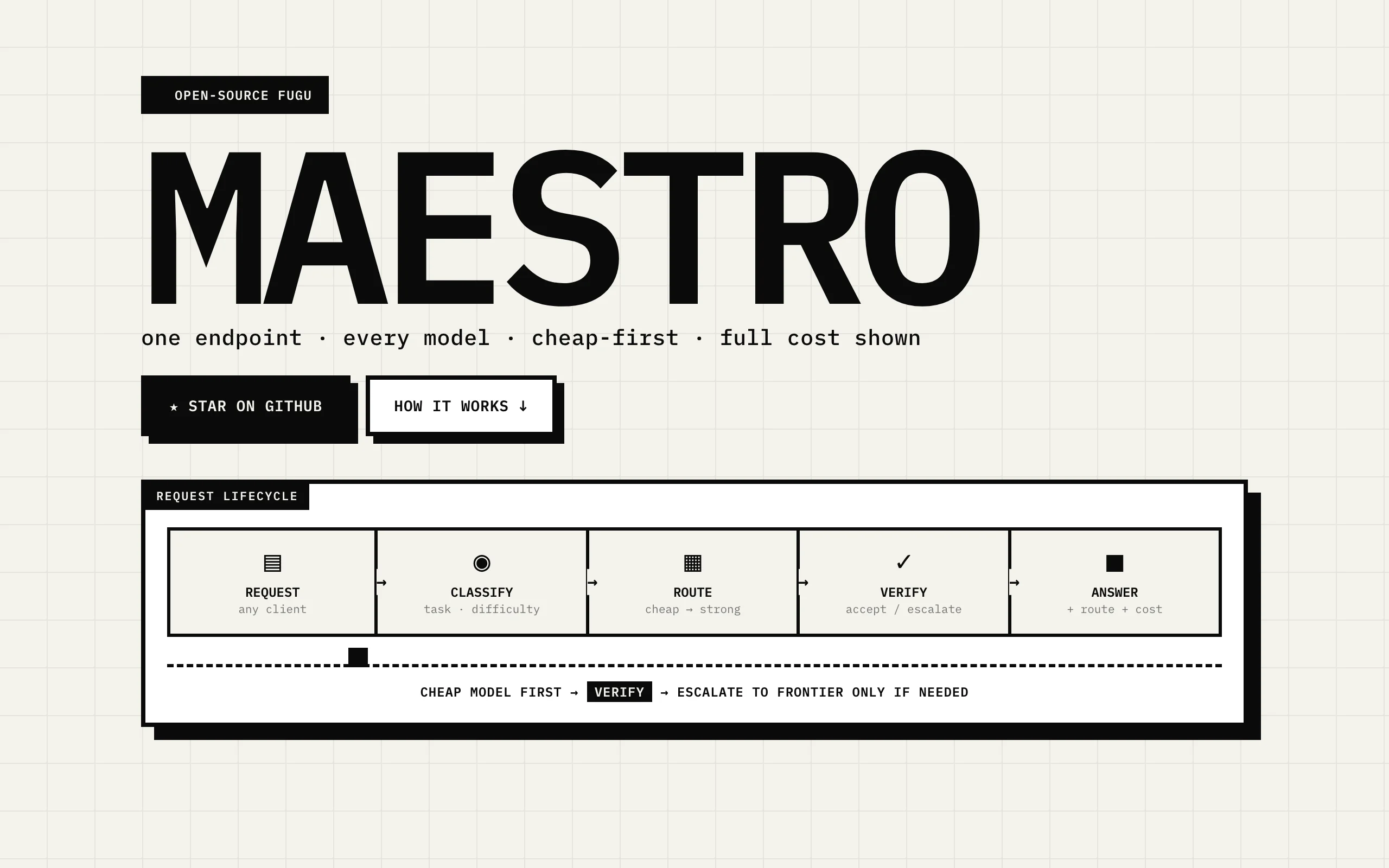
Maestro is "the open source orchestration brain for LLMs." Instead of sending every request to a single expensive model, it routes cheap-first, verifies the answer, and escalates only when the cheap model is not good enough. The differentiator is transparency: every response includes a maestro block showing the route decision, per-model token counts, and the actual cost, so you always know why a request went where it went and what it cost.
It is the open source answer to the closed cheap-first routers that followed Sakana Fugu. If you have been reading Maestro vs Sakana Fugu or Sakana Fugu vs Fable 5, Maestro gives you the same routing philosophy with the code in your hands. It is OpenAI and Anthropic wire-compatible, so you point your base URL at localhost:8080/v1 and existing tools like Claude Code, Cursor, and Continue work unchanged. Disclosure: Maestro is built by AY Automate.
Key features
- Cheap-first, verify, then escalate routing logic
maestrocost-transparency block on every response (route decisions, per-model tokens, cost)- Works with OpenAI, Anthropic, OpenRouter, Vercel AI Gateway, Ollama, vLLM, and llama.cpp
- Model pool "100% yours" via a JSON registry you control
- OpenAI/Anthropic-wire compatible, drops into Claude Code, Cursor, and Continue
- Modes: maestro-auto, maestro-fugu, and maestro-ultra (on the roadmap)
Best for
- Teams that want cheap-first routing without handing control to a closed platform
- Engineers who need a per-request cost breakdown for budgeting and FinOps
- Anyone running a mixed pool of hosted and local models who wants one transparent router
Pricing
- Free, open source, MIT licensed
- Self-hostable: run via
npx openmaestro serveor Docker, no GPU required, one API key
Pros
- Full cost transparency on every call removes the guesswork from LLM spend
- Wire-compatible, so it slots into existing OpenAI/Anthropic tooling with a base-URL change
- Genuinely provider-agnostic, mixing hosted APIs with local Ollama, vLLM, or llama.cpp in one pool
Cons
- Early stage: v0.1, built in roughly five hours, and not yet production-hardened
- The learned router is not built yet, so routing currently relies on a heuristic classifier
- Smaller community and ecosystem than the established tools below
Repo: https://github.com/walidboulanouar/maestro . Site: https://maestro.ayautomate.com .
2. LiteLLM, best for broad provider compatibility
LiteLLM is an open source, OpenAI-compatible proxy and SDK that gives you a single interface to 100+ LLM providers. Instead of writing provider-specific code for OpenAI, Anthropic, Azure, Bedrock, and the rest, you call one API and LiteLLM translates the request to whichever backend you target. It is one of the most widely adopted tools in this space and a common base layer underneath other orchestration setups.
For platform teams, the appeal is consistency. You standardize on the OpenAI request and response format once, then swap or add providers behind it without touching application code.
Key features
- One OpenAI-compatible interface in front of 100+ providers
- Proxy server and Python SDK
- Logging, budgets, and virtual API keys
- Self-hostable
Best for
- Platform teams standardizing many apps on a single LLM interface
- Organizations that need per-key budgets and usage logging across providers
Pricing
- Free, open source, self-hostable
Pros
- The broadest provider coverage in this list, so you rarely hit an unsupported backend
- Budgets and virtual keys make it easy to govern spend across teams
- OpenAI-compatible format means minimal code changes to adopt
Cons
- It is primarily a compatibility and gateway layer, not a cost-optimizing router on its own
- Running the proxy at scale adds an operational component you have to maintain
3. RouteLLM, best for research-grade cost routing
RouteLLM is an open source framework from LMSYS that trains and uses routers to decide, per query, whether a cheaper model can handle the request or whether it needs a stronger, more expensive one. The goal is straightforward: cut cost on the easy majority of queries while preserving quality on the hard ones. Because it comes out of the same group behind widely cited LLM evaluation work, it is a credible, research-grounded approach to the routing problem.
If your interest is the routing decision itself, rather than a full gateway, RouteLLM is the most focused tool here. You can read more on what LLM orchestration is to see where trained routers fit in the bigger picture.
Key features
- Trains and uses routers to classify query difficulty
- Sends easy queries to a cheaper model, hard ones to a strong model
- Research-backed methodology from LMSYS
- Self-hostable framework
Best for
- Teams that want a data-driven router and are comfortable working in Python
- Engineers benchmarking cost-versus-quality trade-offs on their own traffic
Pricing
- Free, open source, self-hostable
Pros
- A principled, research-backed approach to cost routing rather than a hand-tuned heuristic
- Focused scope: it does the routing decision well without imposing a full platform
Cons
- Narrower than a full gateway: you add your own serving, logging, and fallback layers
- Getting the most from trained routers requires representative data and some ML comfort
4. Portkey Gateway, best for production AI gateway features
Portkey Gateway is an open source AI gateway built for production traffic. It handles routing across providers, automatic fallbacks when a provider errors or rate-limits, retries, response caching, and observability, all in one place. There is also a hosted version if you would rather not run it yourself. For teams that have moved past prototyping and need reliability guarantees, it covers the operational concerns that pure routing libraries leave to you.
The reliability features are the draw. Fallbacks and retries keep an app responsive when an upstream provider degrades, and caching trims both latency and cost on repeat queries.
Key features
- Routing and load balancing across providers
- Automatic fallbacks and retries
- Response caching
- Observability and request logging
- Open source, with an optional hosted version
Best for
- Teams running production LLM traffic that need fallbacks and uptime resilience
- Platform engineers who want caching and observability built into the gateway
Pricing
- Free, open source, self-hostable
- Hosted version also available
Pros
- Production-grade reliability features (fallbacks, retries, caching) out of the box
- Built-in observability reduces the need to bolt on separate logging
- Self-host or use the managed version depending on your operational appetite
Cons
- More surface area to configure than a single-purpose routing library
- Cost optimization depends on how you set up routing rules; it is a gateway, not an automatic cheapest-model picker
5. Semantic Router, best for fast intent and decision routing
Semantic Router, from Aurelio, is an open source library that routes requests using semantic embeddings rather than an extra LLM call. You define routes as sets of example utterances, and incoming requests are matched by embedding similarity. Because the decision is a vector comparison, it is fast and deterministic, which makes it well suited to intent classification, guardrails, and steering requests to the right tool or prompt before any expensive generation happens.
This is a different layer from the cost routers above. Where RouteLLM picks a model by difficulty, Semantic Router picks a path by meaning, and the two can work together.
Key features
- Embedding-based routing, no LLM call in the decision path
- Fast, deterministic route selection
- Route definitions from example utterances
- Useful for intent classification and guardrails
Best for
- Teams that need millisecond-level intent routing before generation
- Builders adding deterministic guardrails or tool selection to an LLM app
Pricing
- Free, open source, self-hostable
Pros
- Very fast and deterministic because routing skips the LLM entirely
- Lower cost and latency for the routing decision than model-based classifiers
Cons
- It routes by intent, not by model cost, so it is not a drop-in cheap-first router
- Route quality depends on how well your example utterances cover real inputs
6. LangChain / LangGraph, best for full agent orchestration
LangChain, with its LangGraph extension, is an open source framework for building multi-step LLM applications and stateful agent graphs. It is broader than pure routing: you compose chains, tools, memory, and agents, and with LangGraph you model complex, cyclic, stateful workflows as a graph. If your problem is not "which model answers this request" but "how do I orchestrate a multi-step agent that calls tools, branches, and retains state," this is the heavyweight option. It is a natural fit for AI agent development work.
It supports both Python and JavaScript/TypeScript, with a large ecosystem of integrations.
Key features
- Build multi-step LLM apps with chains, tools, and memory
- LangGraph for stateful, cyclic agent graphs
- Large integration ecosystem
- Python and JS/TS support
Best for
- Teams building agentic, multi-step workflows rather than simple request routing
- Engineers who need branching, state, and tool orchestration in one framework
Pricing
- Free, open source, self-hostable
Pros
- The most complete framework here for genuine agent orchestration and stateful workflows
- Huge ecosystem of integrations and a large community for support
Cons
- Heavier and more abstract than you need if you only want model routing
- The breadth and rate of change can mean a steeper learning curve
7. Ollama, best for local model serving
Ollama is an open source tool for running open models locally with an OpenAI-compatible endpoint. It is not a router itself; it is the piece that makes "run it locally" easy. You pull a model, Ollama serves it on a local API, and any OpenAI-compatible client can call it. In an orchestration setup, Ollama is the "local model" in your pool: the cheapest possible tier that the routers above can send easy or privacy-sensitive requests to before reaching for a hosted API.
For teams pursuing self-hosted LLM orchestration to control cost or keep data on-premises, Ollama is the standard on-ramp.
Key features
- Run open models locally with a single command
- OpenAI-compatible local endpoint
- Cross-platform: macOS, Linux, Windows
- Pairs cleanly with the routers above as the local model in a pool
Best for
- Teams keeping sensitive data on-premises or off third-party APIs
- Anyone wanting a free, local "cheapest tier" in a multi-model routing pool
Pricing
- Free, open source, self-hostable
Pros
- The simplest way to add a local model to your stack
- OpenAI-compatible endpoint means routers and clients work without custom code
Cons
- It serves models; it does not route between them, so you still need an orchestration layer
- Local model quality and speed are bounded by your own hardware
How to choose the best open source LLM orchestration framework
The seven tools above solve overlapping but distinct problems. Use these four questions to narrow down quickly.
1) Do you need a router, a gateway, or an agent framework?
These are three different jobs, and mixing them up is the most common mistake.
- If you need to pick the cheapest capable model per request: start with Maestro or RouteLLM
- If you need provider compatibility, fallbacks, caching, and observability: choose LiteLLM or Portkey Gateway
- If you need multi-step, stateful agent orchestration: use LangChain / LangGraph
2) How much does cost transparency matter?
If finance is asking where the LLM bill comes from, you want per-request visibility, not a monthly aggregate.
- If you need a cost breakdown on every response: Maestro returns route decisions, per-model tokens, and cost inline
- If you mainly need aggregate budgets and per-key spend caps: LiteLLM's budgets and virtual keys cover that
- If you want caching to reduce repeat-query cost: Portkey Gateway handles that at the gateway
3) Cloud APIs, local models, or both?
Self-hosted LLM orchestration usually means a mixed pool, and your router has to support it.
- For local serving as the cheap tier: Ollama (or vLLM / llama.cpp) behind a router
- For a router that spans hosted and local in one pool: Maestro works with OpenAI, Anthropic, OpenRouter, Vercel AI Gateway, Ollama, vLLM, and llama.cpp
- For the widest hosted provider coverage: LiteLLM
4) How production-critical and mature does it need to be?
Maturity is a real trade-off here, so be honest about your risk tolerance.
- For battle-tested production traffic today: LiteLLM, Portkey Gateway, and LangChain are the most established
- For research-grade routing you will tune yourself: RouteLLM
- For the newest cheap-first, transparency-first approach where you accept early-stage status: Maestro (v0.1, not yet production-hardened)
Whatever you pick, run a two-week pilot on your real traffic and measure total cost of ownership, not just the sticker price: routing logic, fallbacks, logging, and the engineering time to run a self-hosted gateway all count.
If you are evaluating open source LLM orchestration tools and want help wiring routing, fallbacks, and a self-hosted model pool into your existing stack, AY Automate can help. We specialize in AI agent development and custom workflow automation, and we build cost-transparent LLM systems around the way your team already works. Book a free discovery call to map out your orchestration and routing strategy.
FAQ
What is open source LLM orchestration? Open source LLM orchestration is the practice of coordinating requests across multiple language models using self-hostable, openly licensed software. Instead of sending every request to one provider, an orchestration layer routes each request to the most appropriate model, handles fallbacks, and often tracks cost. Because the code is open, you can audit, modify, and run it on your own infrastructure.
What is the best open source LLM router? There is no single best open source LLM router; it depends on your goal. Maestro is strong for cheap-first routing with per-response cost transparency, RouteLLM for research-grade cost routing, Semantic Router for fast intent routing, and LiteLLM or Portkey Gateway when you need broad provider compatibility and gateway features. Match the tool to whether you need cost optimization, intent routing, or gateway reliability.
How is an LLM router different from an LLM gateway? A router decides which model should handle a given request, usually based on query difficulty or intent. A gateway sits in front of providers and handles compatibility, fallbacks, retries, caching, and observability, often without making cost-based routing decisions on its own. Many production stacks combine both: a gateway like LiteLLM or Portkey for plumbing, plus a router like Maestro or RouteLLM for cost decisions.
Can I self-host these LLM orchestration tools?
Yes. Every tool in this list is self-hostable and openly licensed, which is the point of self-hosted LLM orchestration. Maestro runs via npx openmaestro serve or Docker with no GPU, Ollama serves models locally, and LiteLLM, RouteLLM, Portkey Gateway, Semantic Router, and LangChain all run on your own infrastructure. Portkey also offers a hosted option if you prefer managed.
How does Maestro compare to Sakana Fugu? Maestro applies the same cheap-first routing idea popularized by Sakana Fugu, but as an MIT-licensed, self-hostable tool with full per-response cost transparency and a model pool you fully control. It is wire-compatible with OpenAI and Anthropic clients. The trade-off is maturity: Maestro is at v0.1 and not yet production-hardened. See Maestro vs Sakana Fugu for a fuller comparison.
Is there a free open source LLM orchestration tool? All seven tools here are free and open source, so you can start without a license fee. Your real costs are infrastructure (hosting the gateway or local models) and the engineering time to set up and maintain routing, fallbacks, and logging. Tools like Ollama even let you run models locally at no per-token cost, which is why they pair so well with cost-first routers.
Should I build my own LLM router or use an existing tool? For most teams, starting with an existing open source tool is faster and lower-risk than building from scratch. Use RouteLLM or Maestro as a base and customize from there. If your needs involve complex routing logic, deep integration, or strict data privacy beyond what off-the-shelf tools offer, that is where a partner doing custom workflow automation can build exactly what you need.
Which open source LLM orchestration tool is best for production? For production traffic today, LiteLLM, Portkey Gateway, and LangChain / LangGraph are the most established and battle-tested. Newer entrants like Maestro bring compelling cost-transparency features but are early stage, so pilot them on non-critical traffic first. Always validate any orchestration tool against your own production patterns before fully committing.
Book a Free Strategy Call
Building this in production?
Walid runs a 30-min call to map your AI engineering team. Free, no slides.

Walid founded AY Automate to help businesses ship AI workflows that actually move revenue. He leads strategy and oversees every client engagement end-to-end.
Full Bio →