Book a Free Strategy Call
Skip the read — talk to Walid in 30 min.
Free strategy call. We map your AI engineering team, you keep the notes.
What Is LLM Orchestration? Routing, Verify-and-Escalate, and Cost Control Explained (2026)
LLM orchestration is the practice of coordinating multiple language-model calls — and often several different models and tools — to complete one task, instead of routing everything to a single model. If you have ever wondered what is LLM orchestration in plain terms, the short answer is this: it is the layer that decides which model handles which request, when to check an answer, and when to spend more money on a stronger model. The llm orchestration meaning that matters most in production is operational, not academic — it is the difference between a demo that calls one expensive model for everything and a system that is cheap, reliable, and fast at scale.
In 2026, llm orchestration has moved from an internal engineering trick to a named product category, with both closed commercial orchestrators and open-source ones competing for the same job. This guide explains the patterns, the architecture, and the vocabulary — vendor-neutral — so you can decide what you actually need.
TL;DR
- LLM orchestration coordinates many model/tool calls to finish a task, rather than sending everything to one model.
- The orchestration layer sits between your application and the model providers and makes runtime decisions: routing, verification, escalation, fallback, caching, and cost tracking.
- The core patterns: routing (pick the right model per request), cheap-first → verify → escalate (try a cheap model, check it, only upgrade if needed), multi-LLM / multi-agent roles (Thinker / Worker / Verifier), fallbacks & retries, caching, and cost/observability controls.
- Three terms people confuse: a framework helps you build orchestrated apps; an orchestration layer / gateway sits in front of providers and routes at runtime; a router is the component that picks the model.
- Teams orchestrate for three reasons: cost, reliability/failover, and quality.
- 2026 split: closed orchestrators (e.g. Sakana Fugu — one API over a hidden pool) vs open ones (e.g. Maestro — self-hosted, transparent receipts).
What Is LLM Orchestration?
LLM orchestration is the coordination of multiple model invocations — sometimes across different providers, sometimes mixed with retrieval, function calls, or other tools — to produce a single useful result. A naive AI feature sends every user request straight to one frontier model and prints whatever comes back. An orchestrated system instead asks a series of questions before, during, and after the call:
- Which model should handle this specific request? (A simple classification does not need your most expensive model.)
- Is the answer good enough, or should I check it?
- If the cheap model failed, do I retry, escalate, or fall back to a different provider?
- Have I seen this request before, and can I serve a cached answer?
- What did this whole task cost, and where did the money and latency go?
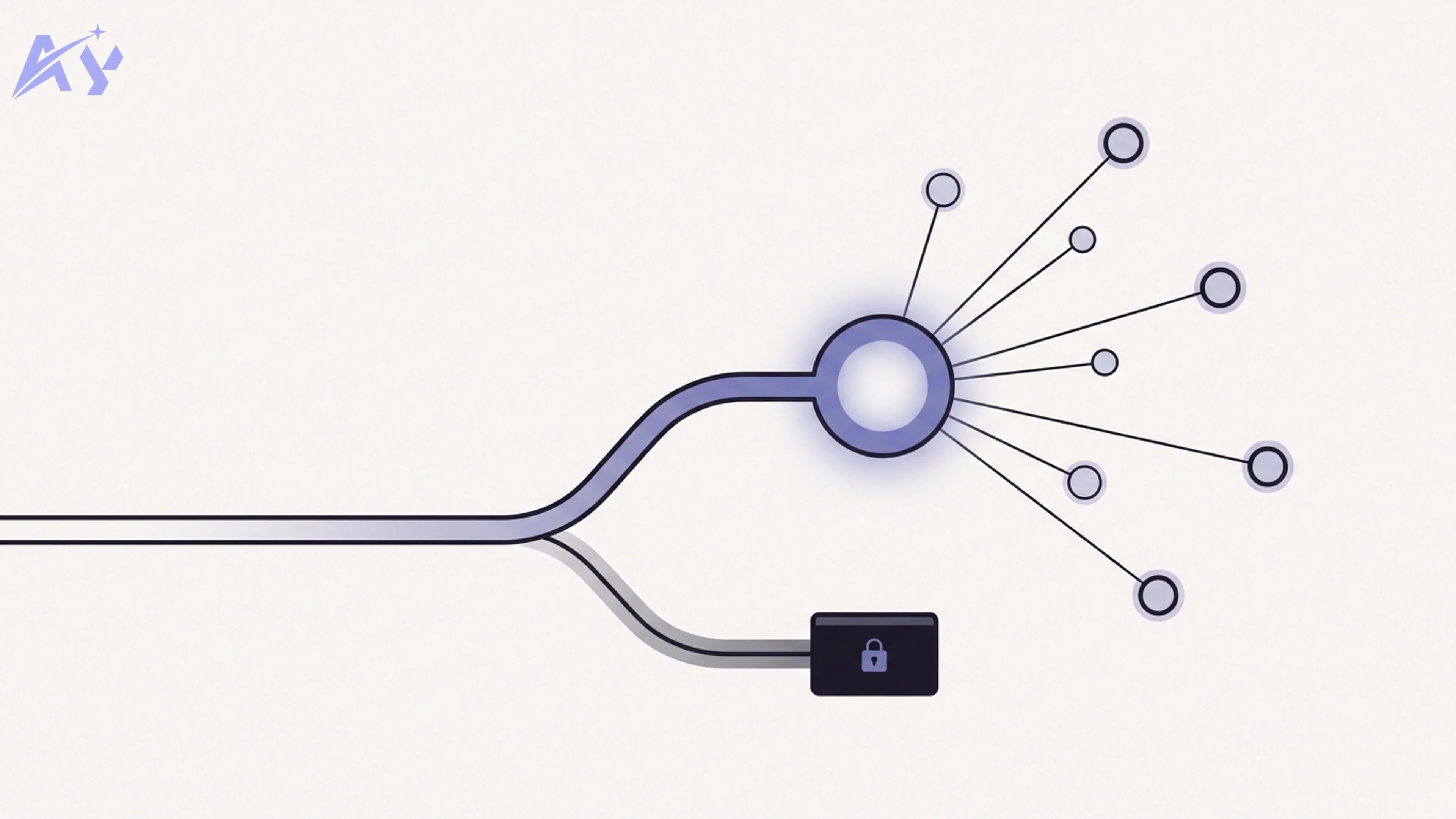
The component that owns these decisions is the orchestration layer. It is a thin piece of infrastructure that sits between your application code and the model APIs. Your app says "answer this"; the orchestration layer decides how — quietly handling model selection, verification, retries, and accounting. From the application's point of view, it is still "call the AI," but underneath, several things may have happened.
That is the whole idea of what does orchestration mean in LLM terms: it is the difference between one call and a coordinated plan of calls.
Why Teams Orchestrate Instead of Using One Model
There are three concrete reasons orchestration earns its keep. None of them are theoretical.
Cost
Frontier models are expensive, and most real workloads are a mix of easy and hard requests. If you send a one-line classification to the same model you use for complex reasoning, you are overpaying — often by 10x or more — on the majority of your traffic. Routing easy work to cheap models and reserving the expensive model for the few requests that need it is the single biggest cost lever in production AI. A good orchestration layer makes that routing automatic instead of something you hardcode and forget.
Reliability and Failover
Depending on a single model — or a single provider — is a single point of failure, and 2026 made that lesson sharp. When the Fable 5 export-control shutdown took a frontier model offline, teams that had wired their entire product to one model endpoint had no graceful path. Teams with an orchestration layer in front of their providers could re-route to an alternate model and keep serving. Failover is not a luxury feature; it is the reason orchestration belongs in front of your providers rather than buried in application code. When one endpoint degrades or disappears, the layer fails over without a redeploy.
Quality
The strongest model is not always the best answer — it is the most expensive answer. Orchestration lets you spend that quality budget where it pays off: route the hard, high-stakes requests to the strong model, verify outputs, and escalate only when a check fails. You get frontier-level quality on the requests that need it without paying frontier prices on the ones that do not.
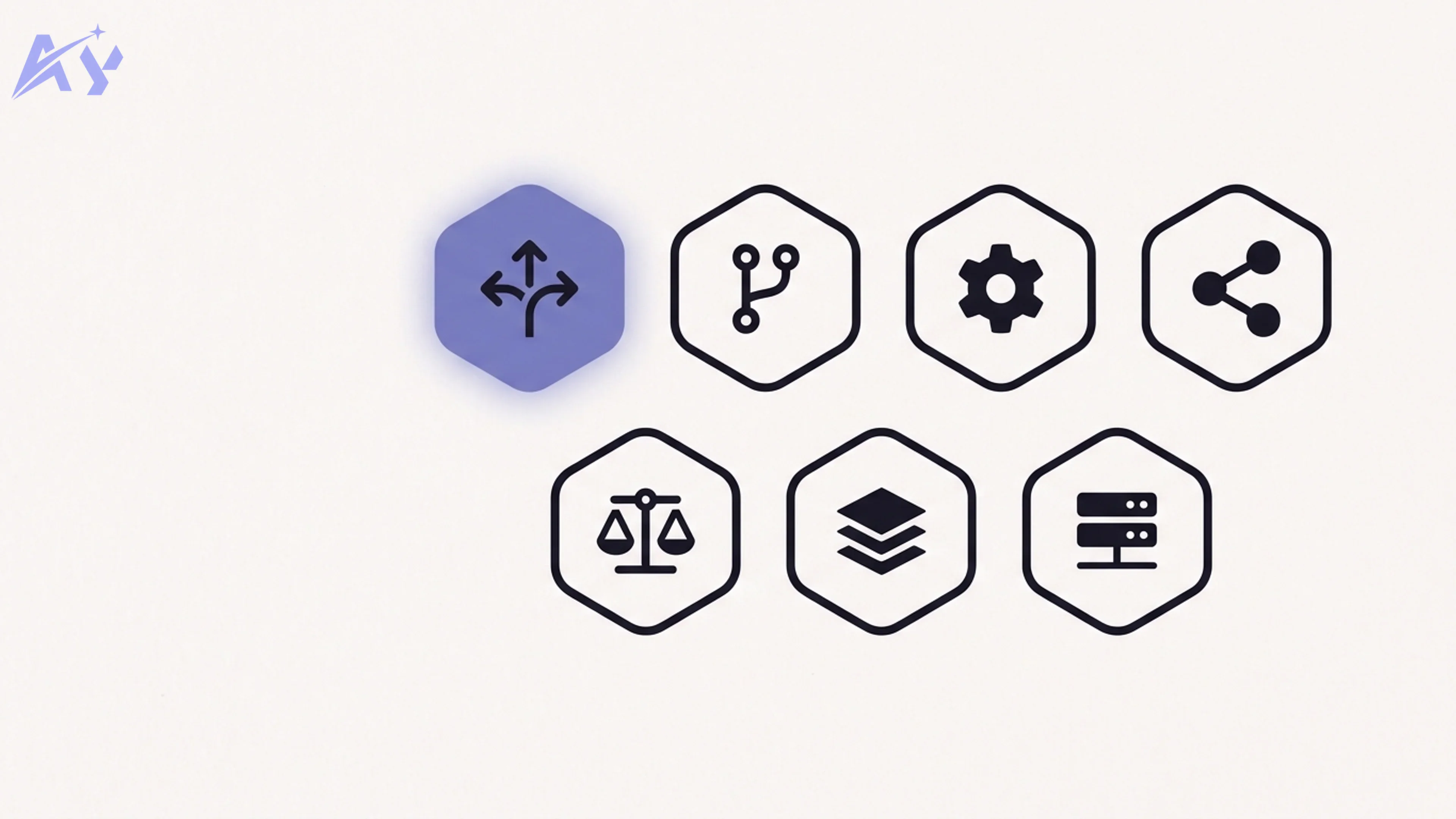
The Core Patterns
These are the building blocks of llm orchestration patterns. Most production systems combine several.
| Pattern | What it does | When to use |
|---|---|---|
| Routing | Picks the right model for each request based on difficulty, cost, or capability | Mixed workloads where most requests are easy and a few are hard |
| Cheap-first → verify → escalate | Tries a cheap model, checks the answer, upgrades to a stronger model only if the check fails | High volume where a large share of answers are "good enough" from a small model |
| Multi-LLM / multi-agent roles | Splits work into roles like Thinker (plan), Worker (execute), Verifier (check) | Complex tasks that benefit from separation of reasoning, execution, and review |
| Fallbacks & retries | Re-routes to an alternate model/provider on error, timeout, or refusal | Reliability-critical systems that cannot go down with one provider |
| Caching | Serves a stored answer for repeated or near-identical requests | Workloads with repeated queries; cuts both cost and latency |
| Cost & observability | Tracks spend, latency, and model choices per request | Any production system — you cannot control what you cannot see |
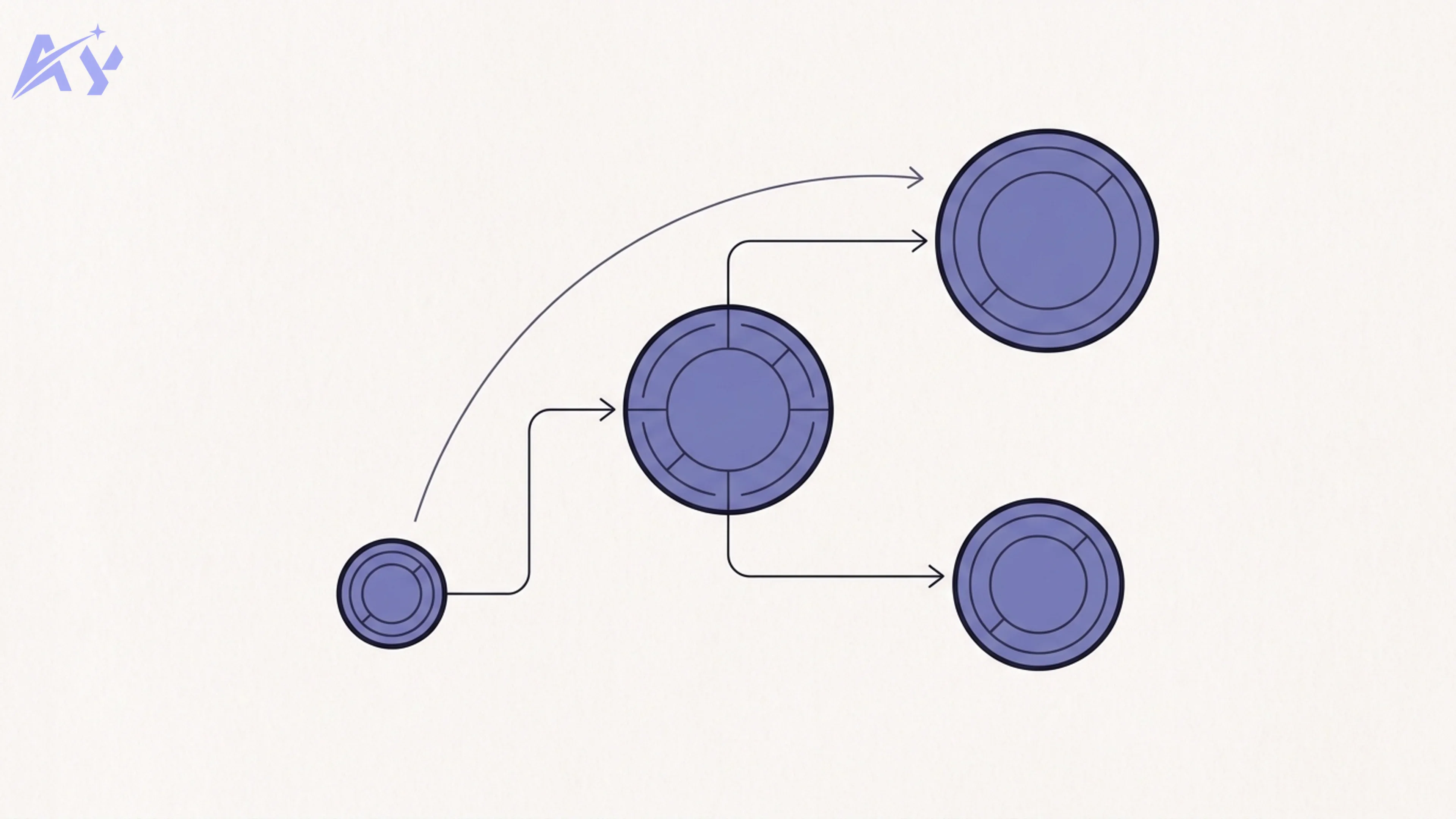
Routing
A router classifies each incoming request and sends it to the most appropriate model. The classification can be by topic, by estimated difficulty, by required capability (vision, code, long context), or simply by cost tier. Routing is the foundation most other patterns build on.
Cheap-First → Verify → Escalate
This is the workhorse pattern for cost control. Send the request to a cheap, fast model first. Then verify the output — with a rubric, a validator, a smaller judge model, or a structured check. If it passes, you are done at a fraction of the cost. If it fails, escalate to a stronger model. On the right workload, the cheap model handles the majority of requests and you only pay frontier prices on the exceptions.
Multi-LLM Roles
Multi-LLM (or multi-agent) orchestration assigns different models to different roles in a task — a common shape is Thinker (decompose and plan), Worker (do the steps), and Verifier (check the result before it ships). This is what people mean by what is multi LLM orchestration: not one model doing everything, but a small team of model calls with distinct jobs, coordinated by the orchestration layer.
Fallbacks, Caching, and Observability
Fallbacks keep you online when a provider fails. Caching cuts cost and latency on repeated work. Observability — per-request logs of which model ran, what it cost, and how long it took — is what turns orchestration from a black box into something you can tune. Together these three are the unglamorous infrastructure that makes the clever patterns safe to run in production.
Framework vs Orchestration Layer vs Router
Three words get used interchangeably and shouldn't be. Here is the clean distinction.
- Framework — A toolkit you use to build orchestrated applications in your own code. Examples of llm orchestration frameworks include LangChain and LangGraph: they give you primitives (chains, graphs, agents, state) to wire up multi-step LLM logic. A framework lives inside your application; you write code against it. When people ask what is llm orchestration framework, this is it — a library for assembling orchestrated flows.
- Orchestration layer / gateway — A service that sits in front of the model providers and makes routing and reliability decisions at runtime. It is a piece of llm orchestration architecture your app talks to instead of talking to providers directly. It decides routing, handles fallback, applies caching, and records cost — without your application needing to know which model actually ran.
- Router — The specific component that picks the model for a given request. A router can live inside a framework or inside a gateway. It is one part of the orchestration layer, not the whole thing.
A useful mental model: a framework is how you write the logic, the orchestration layer is where the runtime decisions happen, and the router is the part that chooses the model. The llm orchestration layer is the piece most people are reaching for when they want cost control and failover without rewriting their app.
For a fuller catalog of the building tools, see this roundup of open-source LLM orchestration and routing tools.
Open vs Closed Orchestration in 2026
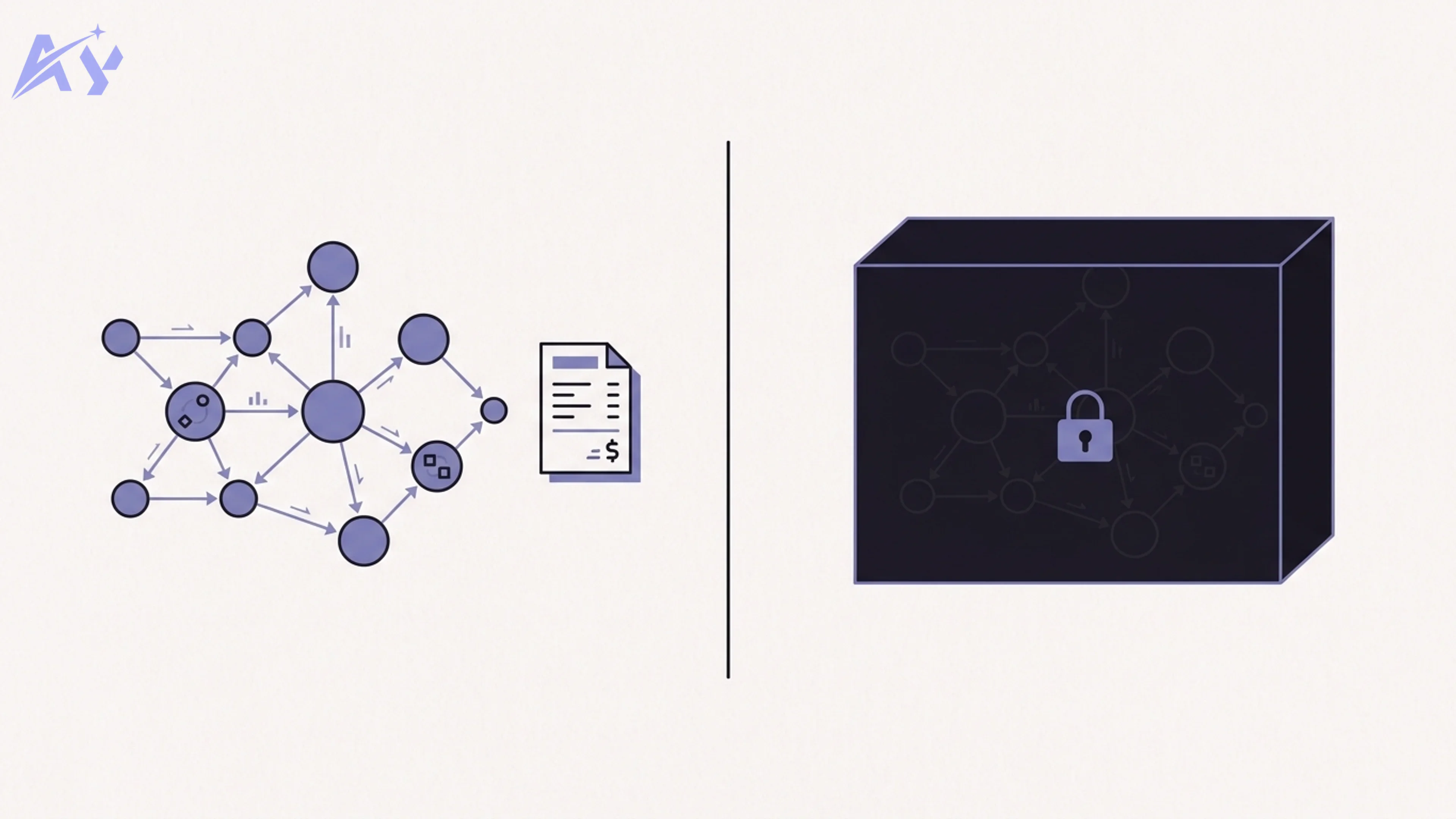
The newest development is that orchestration is now a product you can buy or adopt, not just a pattern you build. Two camps have emerged, and both are legitimate — they make different trade-offs.
Closed orchestration exposes a single API over a hidden, managed pool of models and decides routing for you. Sakana Fugu is the clearest 2026 example: one endpoint that routes each task across a swappable pool of frontier LLMs, with the routing logic and model pool managed behind the scenes. The appeal is simplicity — you call one API and the provider handles the orchestration. The trade-off is transparency and control: you don't fully see which model ran or why, and you're trusting the provider's routing and economics. We cover the details in our look at the closed orchestration model Sakana Fugu.
Open orchestration gives you the orchestration brain as software you run and inspect yourself. Maestro — AY Automate's own open-source project — is an example of this camp: it bills itself as "the open-source orchestration brain for LLMs," is MIT-licensed and self-hostable, and implements the cheap-first → verify → escalate pattern with cost-transparency receipts so you can see exactly which model ran and what each step cost. It is early (v0.1), so treat it as a young project rather than a finished platform — but the design goal is the opposite of a hidden pool: full visibility and self-hosting. The repo is at https://github.com/walidboulanouar/maestro.
The two approaches aren't strictly better or worse — closed orchestrators trade control for convenience, open ones trade convenience for transparency and ownership. If you want a side-by-side, see Maestro vs Sakana Fugu.
How to Get Started
You don't need to adopt a full platform on day one. A sensible progression:
- Measure first. Add observability to your current single-model setup. Log which requests are easy vs hard and what each one costs. You can't route what you can't see.
- Add a fallback. The cheapest reliability win is a second provider you can fail over to. After 2026's shutdown lessons, this alone is worth doing.
- Introduce routing. Send obviously-easy requests to a cheaper model. Start conservative and widen the cheap tier as you gain confidence.
- Layer in verify-and-escalate. Add a check after the cheap model and escalate on failure. This is where the large cost savings come from.
- Decide build vs buy. Use a framework if you want to own the logic in your codebase; adopt an orchestration layer (open or closed) if you want routing and failover as infrastructure.
Bottom Line
LLM orchestration is no longer optional infrastructure for serious AI products. Sending every request to one frontier model is simple, but it is expensive, fragile, and wasteful. Orchestration — routing, cheap-first verify-and-escalate, multi-model roles, fallback, caching, and cost observability — turns that into a system that is cheaper, more reliable, and higher quality where it counts. In 2026 you can build it with a framework, run an open layer like Maestro, or buy a closed one like Sakana Fugu. The right answer depends on how much control and transparency you need — but the question is no longer whether to orchestrate, only how.
FAQ
What is LLM orchestration? LLM orchestration is coordinating multiple model calls — and often multiple models and tools — to complete one task, instead of sending everything to a single model. An orchestration layer makes runtime decisions about routing, verification, escalation, fallback, caching, and cost.
What is an LLM orchestration framework? An LLM orchestration framework is a software toolkit you use to build orchestrated applications in your own code. LangChain and LangGraph are common examples — they provide primitives (chains, graphs, agents, state) for assembling multi-step LLM logic inside your application.
What is an LLM orchestration layer? The LLM orchestration layer is a service that sits between your application and the model providers. It decides which model handles each request, handles fallback when a provider fails, applies caching, and tracks cost — so your app calls "the AI" without knowing which model actually ran.
What is multi-LLM orchestration? Multi-LLM orchestration assigns different models to different roles within a task — for example a Thinker that plans, a Worker that executes, and a Verifier that checks the result. Instead of one model doing everything, a coordinated set of model calls handles distinct jobs.
What does orchestration mean in LLM? In an LLM context, orchestration means coordinating a plan of calls rather than making a single call. It is the layer that decides which model runs, when to verify an answer, when to escalate to a stronger model, and when to fall back to another provider.
What are some LLM orchestration frameworks examples? Common LLM orchestration framework examples include LangChain and LangGraph for building orchestrated flows in code. For an orchestration layer you run as infrastructure, open-source Maestro and closed Sakana Fugu are 2026 examples. See our open-source LLM orchestration and routing tools roundup for more.
What is LLM orchestration architecture? LLM orchestration architecture is the structure that places an orchestration layer between your application and the model providers. That layer contains a router (picks the model), verification and escalation logic, fallback and retry handling, a cache, and cost/observability tracking — coordinating calls across one or more providers.
What are common LLM orchestration patterns? The core LLM orchestration patterns are routing (pick the right model per request), cheap-first → verify → escalate (try a cheap model, check it, upgrade only if needed), multi-LLM/multi-agent roles (Thinker/Worker/Verifier), fallbacks and retries, caching, and cost/observability controls. Most production systems combine several.
Should I build orchestration or buy it? Build with a framework if you want to own the logic in your codebase. Adopt an orchestration layer — open like Maestro or closed like Sakana Fugu — if you want routing, failover, and cost control as infrastructure rather than application code.
Building an Orchestration Layer?
AY Automate designs and builds production multi-model orchestration, routing, and failover for teams that have outgrown single-model setups. We help you cut model spend with cheap-first routing, stay online with provider failover, and keep quality high where it matters — with cost and latency you can actually see. If that is the layer you need, start with AI agent development.
Sources
Book a Free Strategy Call
Building this in production?
Walid runs a 30-min call to map your AI engineering team. Free, no slides.

Adel keeps the engine running at AY Automate. He owns internal processes, team coordination, and the operational excellence that lets us ship fast for clients.